データサイエンスの話
-
1. データサイエンスとは
-
近年、スマートフォンやIoT(モノのインターネット)などの普及により、私たちの周囲では日々膨大なビッグデータが生成されています。このような時代において、ビッグデータに限らず多様なデータを分析し、社会やビジネスの課題解決を図るとともに、これまでにない新たな価値を創出することを目的とする学問分野が「データサイエンス」です。
データサイエンスの基盤となるのは、統計学と機械学習です。収集されたデータには誤差やばらつきが含まれることが多く、統計学はデータの性質を正しく理解し、説明や解釈を重視します。一方、機械学習は自動で学習を行い、モデルの予測精度を高めることに重点を置きます。
日本においては、データサイエンスという分野自体が比較的新しく、2017年に滋賀大学において国内初のデータサイエンス学部が設立されました。データサイエンティストの育成に関しては、アメリカなどの先進国と比べて大きく遅れをとっているのが現状です。 -
-
2. 機械学習
-
機械学習は教師あり学習(Supervised Learning)、教師なし学習(Unsupervised Learning)、強化学習(Reinforcement Learning)の3つに大別されます。教師あり学習は入力データと、それに対応する出力データ(正解付き)のペアを用いて学習し、株価や売上などの数値を予測する「回帰」や、画像認識(画像中の犬、猫等を認識する)などの「分類」に使われます。教師なし学習は正解が与えられていない入力データだけを用いて、データ内に潜むパターンや構造を見つける手法で、データの要約である「次元削減」や、グループ分けの「クラスタリング」に使われます。強化学習は試行錯誤を通じて「報酬」が最大になるよう行動を学習します。例としては自動車の自動運転があります。
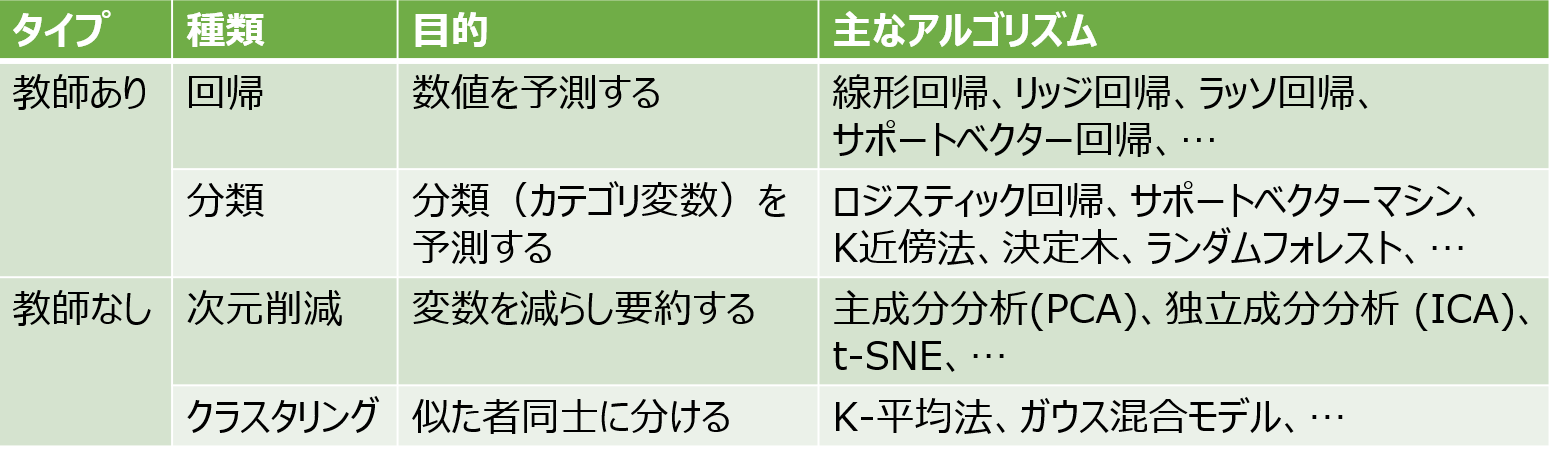 今回はこの中から次元削減の手法である主成分分析(PCA)を取り上げます。
今回はこの中から次元削減の手法である主成分分析(PCA)を取り上げます。 -
-
3. 主成分分析
-
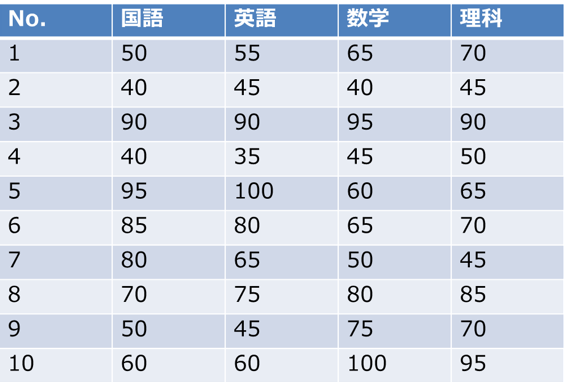
主成分分析は、多くの変数の持つ情報を、できるだけ損なうことなしに、より少ない次元の合成変数(主成分)へ要約する手法です。たとえば、 生徒10人の国語・英語・数学・理科の成績データを考えてみましょう。計算手法としては、分散が最大となる方向(軸)を見つけ、その軸を第1主成分とします。次に第1主成分と直交する条件のもとで分散を最大とするような軸を求め、これを第2主成分とします。主成分分析は固有値および固有ベクトルを求める問題に帰着されます。
 第1主成分得点を横軸に、第2主成分得点を縦軸にとって散布図を描くと、第1主成分は右にいくほど総合的な学力が高く、第2主成分は上にいくほど文系傾向、下にいくほど理系傾向が強いと解釈できます。元の4つの変数(国語・英語・数学・理科)の情報を、2つの合成変数で大まかに把握することができました。これが次元を削減したという意味になります。
第1主成分得点を横軸に、第2主成分得点を縦軸にとって散布図を描くと、第1主成分は右にいくほど総合的な学力が高く、第2主成分は上にいくほど文系傾向、下にいくほど理系傾向が強いと解釈できます。元の4つの変数(国語・英語・数学・理科)の情報を、2つの合成変数で大まかに把握することができました。これが次元を削減したという意味になります。
また主成分分析は流体力学の分野では固有直交分解(Proper Orthogonal Decomposition, POD)として知られており、さらに時空間データに対して情報を抽出できる、動的モード分解(Dynamic Mode Decomposition, DMD)も次元削減の手法として用いられています。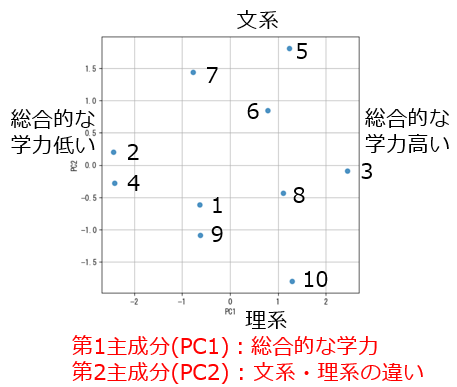
-
4. データサイエンス・AI講座
弊社では、データサイエンスおよびAIに関する講座を開催しております。ご要望に応じて、Pythonや統計学を含めたカスタマイズ講習も承っておりますので、お気軽にお問い合わせください。